What is CogStack?
CogStack is an information extraction and retrieval ecosystem, which uses enterprise search, natural language processing, analytics and visualisation technologies to unlock the health record and assist in clinical decision making and research.
CogStack comprises of multiple components, selection of which depends on a particular use-case. It is usually deployed as a Platform-as-a-Service on a local infrastructure, but can be also deployed in the cloud. Currently, each service runs in a container that is managed by Docker engine.
Key resources
The official website: https://cogstack.org/
The official GitHub repository: https://github.com/CogStack
The official Docker Hub repository: https://hub.docker.com/u/cogstacksystems
Twitter: https://twitter.com/cogstack
Related publications
Jackson, Richard, et al. “CogStack-experiences of deploying integrated information retrieval and extraction services in a large National Health Service Foundation Trust hospital.” BMC medical informatics and decision making 18.1 (2018): 47. https://doi.org/10.1186/s12911-018-0623-9
Wu, Honghan, et al. “SemEHR: A general-purpose semantic search system to surface semantic data from clinical notes for tailored care, trial recruitment, and clinical research.” Journal of the American Medical Informatics Association 25.5 (2018): 530-537. https://doi.org/10.1093/jamia/ocx160
Wu, Honghan, et al. “SemEHR: surfacing semantic data from clinical notes in electronic health records for tailored care, trial recruitment, and clinical research.” The Lancet 390 (2017): S97. https://doi.org/10.1016/S0140-6736(17)33032-5
Bean, Daniel M., et al. “Semantic computational analysis of anticoagulation use in atrial fibrillation from real world data.” PloS one 14.11 (2019). https://doi.org/10.1371/journal.pone.0225625
Searle, Thomas, et al. “MedCATTrainer: A Biomedical Free Text Annotation Interface with Active Learning and Research Use Case Specific Customisation.” arXiv preprint arXiv:1907.07322 (2019). https://arxiv.org/abs/1907.07322
Kraljevic, Zeljko, et al. “MedCAT–Medical Concept Annotation Tool.” arXiv preprint arXiv:1912.10166 (2019). https://arxiv.org/abs/1912.10166
Tissot, Hegler, et al. “Natural Language Processing for Mimicking Clinical Trial Recruitment in Critical Care: A Semi-automated Simulation Based on the LeoPARDS Trial.” IEEE Journal of Biomedical and Health Informatics (2020), doi: 10.1109/JBHI.2020.2977925. https://doi.org/10.1101/19005603
Bean, Daniel, et al. (2020) “ACE-inhibitors and Angiotensin-2 Receptor Blockers are not associated with severe SARS- COVID19 infection in a multi-site UK acute Hospital Trust.” medRxiv 2020.04.07.20056788. https://doi.org/10.1101/2020.04.07.20056788
Carr, Ewan, et al. (2020) “Supplementing the National Early Warning Score (NEWS2) for anticipating early deterioration among patients with COVID-19 infection.” medRxiv 2020.04.24.20078006. https://doi.org/10.1101/2020.04.24.20078006
Zhang, Huayu, et al. (2020) “Risk prediction for poor outcome and death in hospital in-patients with COVID-19: derivation in Wuhan, China and external validation in London, UK.” medRxiv 2020.04.28.20082222. https://doi.org/10.1101/2020.04.28.20082222
Further reading
Tutorial: MedCAT – Analysing Electronic Health Records (in a series of articles)
Tutorial: MedCAT Trainer: A Tool For Inspecting, Improving and Customising MedCAT
CogStack ecosystem
CogStack comprises of multiple services selection of which depends on a particular use-case. The best is to think of CogStack is as a set (or stack) of technologies (or services, “cogs”) that are deployed together as a toolbox empowering one to unlock the information from electronic health record (EHR) data.
CogStack comprises both of back-end and front-end services. The back-end stack includes tools for EHR data ingestion, storage, information extraction and natural language processing (NLP). The front-end includes tools for defining and monitoring the data flows, querying, visualising and working with the processed data. Apart from that, the front-end can include tools for training NLP models and refining NLP algorithms. CogStack also defines a a set of APIs to facilitate data exchange between different components and a uniform pipeline engine to serve as a “glue” between the data processing components.
Example use-case
Most commonly the EHR information is modelled and stored in relational database systems. Although most of the information is represented in structured form, there is a large untapped value stored as free-text notes. The notes reside alongside the structured information in the system, but very often these are stored in some binary document format (such as MS Word, PDF, scanned images) either as BLOB types in the database or are linked to external filesystem. Searching through the notes can be troublesome requiring each document or note to be opened manually. Moreover, the notes can contain errors, misspellings, abbreviations and hence may require disambiguation for extracting the relevant medical concepts. Information retrieval capabilities from free-text notes are hence very limited in such scenarios.
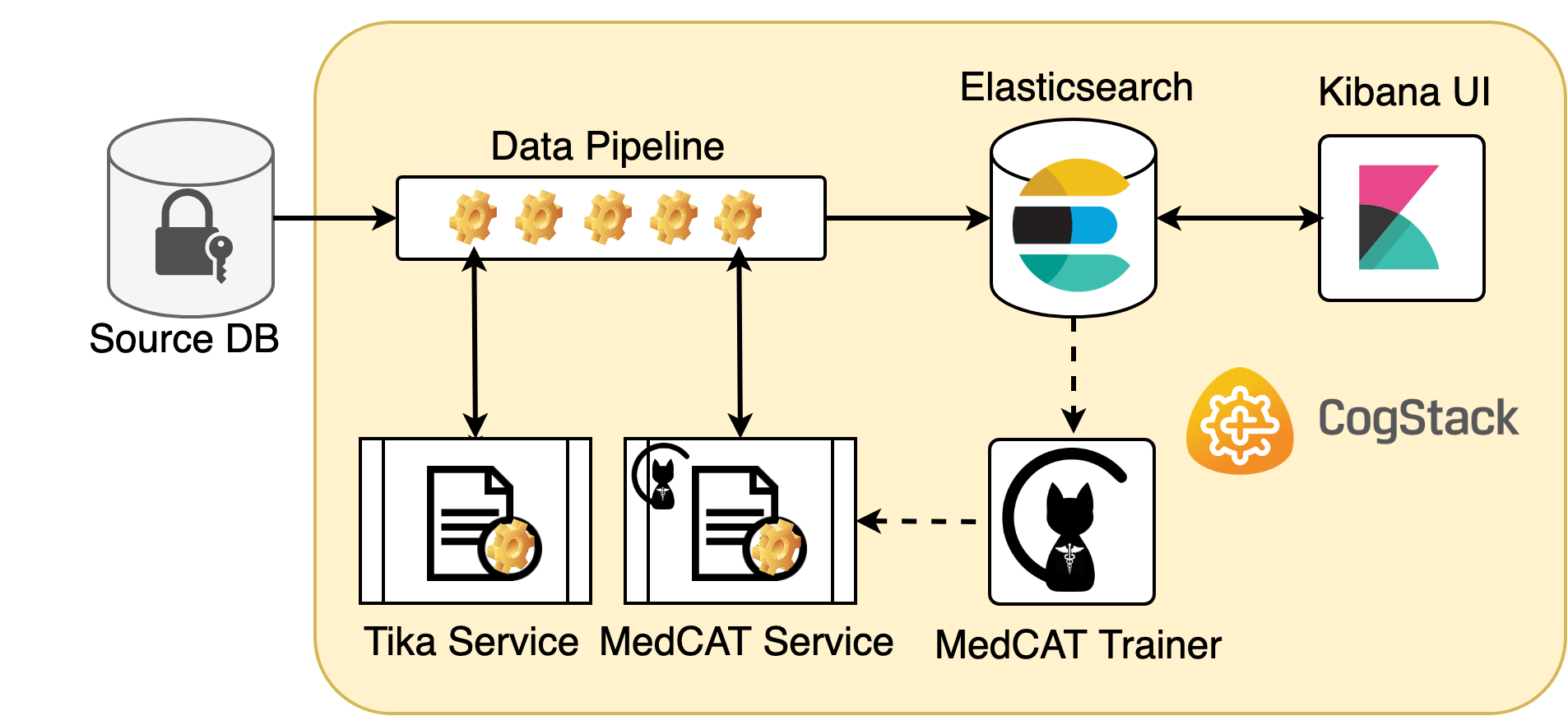
Assuming that the required data governance protocols are already in place, one may consider a following CogStack deployment to unlock the untapped value in EHR data.
An example deployment of CogStack would consist of services running on back-end:
ElasticSearch – the primary NoSQL data store and search engine, where all the EHR data will be stored for querying and analysis.
Data pipelines engine (Apache NiFi) – performing ingestion of EHR data to ElasticSearch with necessary Extract-Transform-Load (ETL) operations.
Tika Service - performing extraction of the text from binary documents using Apache Tika.
NLP Service – usually, this will be a Medical Concept Annotation Tool (MedCAT) with a model trained on a corpus of documents and using a concept dictionary (such as UMLS or SNOMED CT) that will be used to extract the medical concepts from the clinical notes. In our case MedCAT model is served via MedCAT Service.
and services running on front-end:
Kibana - a user interface for querying, analysing and visualising the data ingested into ElasticSearch.
MedCAT Trainer - a dedicated user interface for training the MedCAT models. The refined models can be later plugged in to MedCAT Service to run as a part of data processing pipeline or can be directly used in analyses in custom applications.
All the mentioned services would be running in containers and being orchestrated by Docker engine.
| Tip |
|---|
Please see CogStack using Apache NiFi Deployment Examples for a documentation on such a deployment. |
| Info |
|---|
Please note that although we provide a set of example template deployments, each component need to be configured and its functionality tailored to use-case specific requirements. Some of these works will include setting-up the data pipelines according to the specifications of the used EHR data sources, setting up the NLP application with the desired models and/or resources, setting up and tailoring the services security layer in accordance to the requirements and approved information governance. |