| Anchor | ||||
|---|---|---|---|---|
|
The most convenient way to get the newest version of CogStack bundle is to download it directly from the official github repository:
wget 'https://github.com/CogStack/CogStack-Pipeline/releases/download/1.3.0/cogstack-pipeline-1.3.0-opejndk11.tar.gz'
unzip cogstack-pipeline-1.3.0-opejndk11.tar.gz
The content will be decompressed into CogStack-Pipeline-1.3.0/ directory.
| Anchor | ||||
|---|---|---|---|---|
|
Data processing workflow
The data processing workflow of CogStack is based on Java Spring Batch framework. Not to dwell too much into technical details and just to give a general idea – the data is being read from a predefined data source, later it follows a number of processing operations with the final result stored in a predefined data sink. CogStack implements variety of data processors, data readers and writers with scalability mechanisms that can be selected in CogStack job configuration. Although the data can be possibly read from different sources, the most frequently used data sink is ElasicSearch. For more details about the CogStack functionality, please refer to the other parts of the documentation.
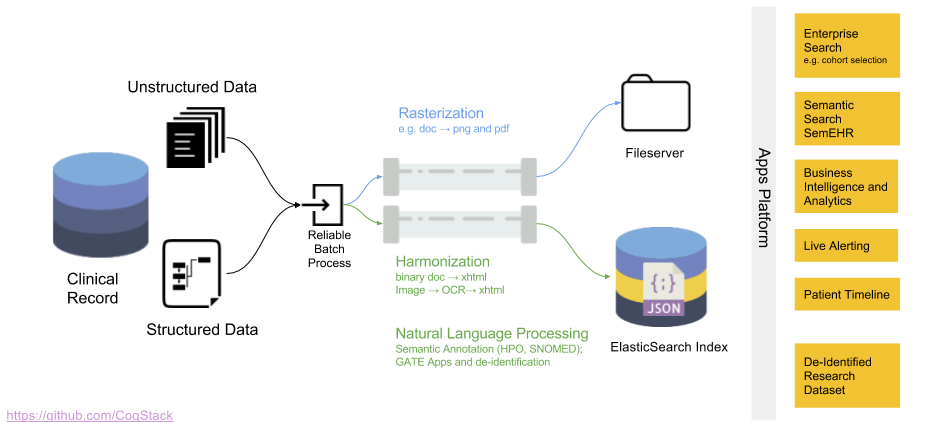
In this tutorial we only focus on a simple and very common use-case, where CogStack reads and process structured and free-text EHRs data from a single PostgreSQL database. The result is then stored in ElasticSearch where the data can be easily queried in Kibana dashboard. However, CogStack engine also supports multiple data sources – please see Example 3 (from Examples section) which covers such case.
CogStack ecosystem
CogStack ecosystem consists of multiple inter-connected microservices running together. For the ease of use and deployment we use Docker (more specifically, Docker Compose), and provide Compose files for configuring and running the microservices. The selection of running microservices depends mostly on the specification of EHR data source(s), data extraction and processing requirements.
In this tutorial the CogStack ecosystem is composed of the following microservices:
samples-db– PostgreSQL database loaded with a sample dataset underdb_samplesname,cogstack-pipeline– CogStack data processing engine with worker(s),cogstack-job-repo– PostgreSQL database for storing information about CogStack jobs,elasticsearch-1– ElasticSearch search engine (single node) for storing and querying the processed EHR data,kibana– Kibana data visualization tool for querying the data from ElasticSearch.
Since all the examples share the common configuration for the microservices used, the base Docker Compose file is provided in examples/docker-common/docker-compose.yml. The Docker Compose file with configuration of microservices being overriden for this example can be found in examples/example2/docker/docker-compose.override.yml. Both configuration files are automatically used by Docker Compose when deploying CogStack, as will be shown later.
For a more detailed description of used microservices in CogStack ecosystem, please refer to CogStack platformecosystem (v1) part.
| Info | ||
|---|---|---|
| ||
In some more advanced deployments, the Nginx reverse proxy and/or Fluentd logging services are used – for more details, please see Example 6 or Example 7 in the Examples section. |
| Anchor | ||||
|---|---|---|---|---|
|
The sample dataset used in this tutorial consists of two types of EHR data:
- Synthetic – structured, synthetic EHRs, generated using synthea application,
- Medial reports – unstructured, medical health report documents obtained from MTSamples.
These datasets, although unrelated, are used together to compose a combined dataset.
Synthetic – synthea-based
This dataset consists of synthetic EHRs that were generated using synthea application – the synthetic patient generator that models the medical history of generated patients. For this tutorial, we generated EHRs for 100 patients and exported them as CSV files. Typed in the main synthea directory, the command line for running it:
./run_synthea -p 100 \
--generate.append_numbers_to_person_names=false \
--exporter.csv.export=true
However, the pre-generated files are provided in a compressed form as examples/rawdata/synsamples.tgz file.
The generated dataset consists of the following files:
allergies.csv– Patient allergy data,careplans.csv– Patient care plan data, including goals,conditions.csv– Patient conditions or diagnoses,encounters.csv– Patient encounter data,imaging_studies.csv– Patient imaging metadata,immunizations.csv– Patient immunization data,medications.csv– Patient medication data,observations.csv– Patient observations including vital signs and lab reports,patients.csv– Patient demographic data,procedures.csv– Patient procedure data including surgeries.
For more details about the generated files and the schema definition please refer to the official synthea wiki page. The sample records are shown in Advanced: preparing a DB schema for CogStack part.
In this example we use a subset of the available data – as a simple use-case, only patients.csv, encounters.csv and observations.csv file are used related. These files also represent separate tables in the db_samples database. For more advanced use-cases please check the Example 3 from the Examples section which uses the full dataset.
Medical reports – MTSamples
MTSamples is a collection of transcribed medical sample reports and examples. The reports are in a free-text format and have been downloaded directly from the official website.
Each report contain such information as:
- Sample Type,
- Medical Specialty,
- Sample Name,
- Short Description,
- Medical Transcription Sample Report (in free text format).
The collection comprises in total of 4873 documents. A sample document is shown in Advanced: preparing a DB schema for CogStack part.
Preparing the data
For the ease of use a database dump with predefined schema and preloaded data will be provided in examples/example2/db_dump directory. This way, the PostgreSQL database will be automatically initialized when deployed using Docker. The database dump for this example (alongside the others) can be also directly downloaded from Amazon S3 by running in the main examples/ directory:
bash download_db_dumps.sh
Alternatively, the PostgreSQL database schema definition used in this tutorial db_create_schema.sqlis stored in examples/example2/extra/ directory alongside the script prepare_db.sh to generate the database dump. More information covering the creation of database schema can be found in Advanced: preparing a DB schema for CogStack part.
| Anchor | ||||
|---|---|---|---|---|
|
Running CogStack for the first time
For the ease of use CogStack is being deployed and run using Docker. However, before starting the CogStack ecosystem for the first time, one needs to have the database dump files for sample data either by creating them locally or downloading from Amazon S3. To download the database dumps, just type in the main examples/ directory:
bash download_db_dumps.sh
Next, a setup scripts needs to be run locally to prepare the Docker images and configuration files for CogStack data processing engine. The script is available in examples/example2/ path and can be run as:
bash setup.sh
As a result, a temporary directory __deploy/ will be created containing all the necessary artifacts to deploy CogStack. More information about running CogStack and available options can be found in Running CogStack part.
Docker-based deployment
Next, we can proceed to deploy CogStack ecosystem using Docker Compose. It will configure and start microservices based on the provided Compose files:
- common base configuration, copied from
examples/docker-common/docker-compose.yml, - example-specific configuration copied from
examples/example2/docker/docker-compose.override.yml.
Moreover, the PostgreSQL database container comes with pre-initialized database dump ready to be loaded directly into.
In order to run CogStack, type in the examples/example2/__deploy/ directory:
docker-compose up
In the console there will be printed status logs of the currently running microservices. For the moment, however, they may be not very informative (we’re working on that).
| Info | ||
|---|---|---|
| ||
Example 7 (seethe Examples section) covers a deployment use-case with advanced logging and parsing of the coming messages. |
Connecting to the microservices
CogStack ecosystem
The picture below sketches a general idea on how the microservices are running and communicating within a sample CogStack ecosystem used in this tutorial.
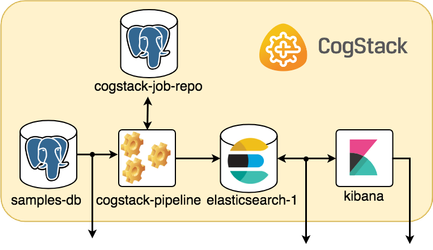
Assuming that everything is working fine, we should be able to connect to the running microservices.
Kibana and ElasticSearch
Kibana dashboard used to query the EHRs can be accessed directly in browser via URL: http://localhost:5601/. The data can be queried using a number of ElasticSearch indices, e.g. sample_observations_view. Usually, each index will correspond to the database view in db_samples (samples-db PostgreSQL database) from which the data was ingested. However, when entering Kibana dashboard for the first time, an index pattern needs to be configured in the Kibana management panel – for more information about its creation, please refer to the official Kibana documentation.
In addition, ElasticSearch REST end-point can be accessed via URL http://localhost:9200/. It can be used to perform manual queries or to be used by other external services – for example, one can list the available indices:
curl 'http://localhost:9200/_cat/indices'
or query one of the available indices – sample_observations_view:
curl 'http://localhost:9200/sample_observations_view'
For more information about possible documents querying or modification operations, please refer to the official ElasticSearch documentation.
As a side note, the name for ElasticSearch node in the Docker Compose has been set as elasticsearch-1. The -1 ending emphasizes that for larger-scale deployments, multiple ElasticSearch nodes can be used – typically, a minimum of 3.
PostgreSQL sample database
Moreover, the access PostgreSQL database with the input sample data is exposed directly at localhost:5555. The database name is db_sample with user test and password test. To connect, one can run:
psql -U 'test' -W -d 'db_samples' -h localhost -p 5555
| Tip | ||
|---|---|---|
| ||
The information about connecting to the micro-services and resources will become useful in Advanced: preparing a configuration file for CogStack part. |
| Anchor | ||||
|---|---|---|---|---|
|
General information
In the current implementation, CogStack can only ingest EHR data from a specified input database and relation. This is why, in order to process the sample patient data covered in this tutorial, one needs to create an appropriate database schema and load the data.
Moreover, as relational join statements have a high performance burden for ElasticSearch, the EHR data is best to be stored denormalized in ElasticSearch. This is why, for the moment, we rely on ingesting the data from additional view(s) created in the sample database.
Following, we cover the process of defining the required schema step-by-step.
Database schema – tables
Patients table
The first 5 records of patient data (file: patients.csv from Synthea-based samples) in CSV format is presented below:
| Code Block | ||||
|---|---|---|---|---|
| ||||
ID,BIRTHDATE,DEATHDATE,SSN,DRIVERS,PASSPORT,PREFIX,FIRST,LAST,SUFFIX,MAIDEN,MARITAL,RACE,ETHNICITY,GENDER,BIRTHPLACE,ADDRESS,CITY,STATE,ZIP b9f5a11b-211d-4ced-b3ba-12012c83b937,1939-08-04,1996-03-15,999-11-9633,S99999830,X106007X,Mr.,Brady,Lynch,,,M,white,polish,M,Worcester,701 Schiller Esplanade,Fitchburg,Massachusetts,01420 fab43860-c3be-4808-b7b4-00423c02816b,1962-06-21,2011-03-10,999-67-8307,S99958025,X26840237X,Mrs.,Antonia,Benavides,,Padrón,M,hispanic,mexican,F,Rockland,643 Hand Bay,Boston,Massachusetts,02108 84dd6378-2ddc-44b6-9292-2a4461bcef53,1998-12-01,,999-50-5147,S99987241,,Mr.,Keith,Conn,,,,white,english,M,Rockland,461 Spinka Extension Suite 69,Framingham,Massachusetts,01701 9929044f-1f43-4453-b2c0-a2f45dcdd4be,2014-09-23,,999-64-4171,,,,Derrick,Lakin,,,,white,irish,M,Tewksbury,577 Hessel Lane,Hampden,Massachusetts, |
The patients table definition in PostgreSQL according to the specification:
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
CREATE TABLE patients ( id UUID PRIMARY KEY, birthdate DATE NOT NULL, deathdate DATE, ssn VARCHAR(64) NOT NULL, drivers VARCHAR(64), passport VARCHAR(64), prefix VARCHAR(8), first VARCHAR(64) NOT NULL, last VARCHAR(64) NOT NULL, suffix VARCHAR(8), maiden VARCHAR(64), marital CHAR(1), race VARCHAR(64) NOT NULL, ethnicity VARCHAR(64) NOT NULL, gender CHAR(1) NOT NULL, birthplace VARCHAR(64) NOT NULL, address VARCHAR(64) NOT NULL, city VARCHAR(64) NOT NULL, state VARCHAR(64) NOT NULL, zip VARCHAR(64) ) ; |
Encounters table
Similarly, the first 5 records of patient encounters data (file: encounters.csv)
| Code Block | ||||
|---|---|---|---|---|
| ||||
ID,START,STOP,PATIENT,CODE,DESCRIPTION,COST,REASONCODE,REASONDESCRIPTION 123ffd84-618e-47cd-abca-5fe95b72179a,1955-07-30T07:30Z,1955-07-30T07:45Z,b9f5a11b-211d-4ced-b3ba-12012c83b937,185345009,Encounter for symptom,129.16,36971009,Sinusitis (disorder) 66b016e9-e797-446a-8f2b-e5534acbbb04,1962-03-09T07:30Z,1962-03-09T07:45Z,b9f5a11b-211d-4ced-b3ba-12012c83b937,185349003,Encounter for check up (procedure),129.16,, d517437d-50b5-4cab-aca2-9c010c06989e,1983-08-19T07:30Z,1983-08-19T08:00Z,b9f5a11b-211d-4ced-b3ba-12012c83b937,185349003,Encounter for check up (procedure),129.16,, 2452cf09-021b-4586-9e33-59d7d2242f31,1987-08-28T07:30Z,1987-08-28T07:45Z,b9f5a11b-211d-4ced-b3ba-12012c83b937,185349003,Encounter for check up (procedure),129.16,, f25a828f-ae79-4dd0-b6eb-bca26138421b,1969-09-13T14:02Z,1969-09-13T14:34Z,fab43860-c3be-4808-b7b4-00423c02816b,185345009,Encounter for symptom,129.16,10509002,Acute bronchitis (disorder) |
with the corresponding encounters table definition:
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
CREATE TABLE encounters ( id UUID PRIMARY KEY NOT NULL, start TIMESTAMP NOT NULL, stop TIMESTAMP, patient UUID REFERENCES patients, code VARCHAR(64) NOT NULL, description VARCHAR(256) NOT NULL, cost REAL NOT NULL, reasoncode VARCHAR(64), reasondescription VARCHAR(256), document TEXT --(*) ) ; |
Here, with--(*)has been marked an additional document field. This extra field will be used to store a document from MTSamples dataset.
| Info | ||
|---|---|---|
| ||
Just to clarify, Synthea-based and MTSamples are two unrelated datasets. Here, we are extending the synthetic dataset with the clinical documents from the MTSamples to create a combined one, to be able to perform more advanced queries. |
A sample document from MTSamples dataset is presented below:
| Code Block | ||||
|---|---|---|---|---|
| ||||
Sample Type / Medical Specialty: Allergy / Immunology Sample Name: Allergic Rhinitis Description: A 23-year-old white female presents with complaint of allergies. (Medical Transcription Sample Report) SUBJECTIVE: This 23-year-old white female presents with complaint of allergies. She used to have allergies when she lived in Seattle but she thinks they are worse here. In the past, she has tried Claritin, and Zyrtec. Both worked for short time but then seemed to lose effectiveness. She has used Allegra also. She used that last summer and she began using it again two weeks ago. It does not appear to be working very well. She has used over-the-counter sprays but no prescription nasal sprays. She does have asthma but doest not require daily medication for this and does not think it is flaring up. MEDICATIONS: Her only medication currently is Ortho Tri-Cyclen and the Allegra. ALLERGIES: She has no known medicine allergies. OBJECTIVE: Vitals: Weight was 130 pounds and blood pressure 124/78. HEENT: Her throat was mildly erythematous without exudate. Nasal mucosa was erythematous and swollen. Only clear drainage was seen. TMs were clear. Neck: Supple without adenopathy. Lungs: Clear. ASSESSMENT: Allergic rhinitis. PLAN: 1. She will try Zyrtec instead of Allegra again. Another option will be to use loratadine. She does not think she has prescription coverage so that might be cheaper. 2. Samples of Nasonex two sprays in each nostril given for three weeks. A prescription was written as well. Keywords: allergy / immunology, allergic rhinitis, allergies, asthma, nasal sprays, rhinitis, nasal, erythematous, allegra, sprays, allergic, |
Observations table
The next table is observations, where the first 5 rows of observations.csv file are:
| Code Block | ||||
|---|---|---|---|---|
| ||||
DATE,PATIENT,ENCOUNTER,CODE,DESCRIPTION,VALUE,UNITS,TYPE 1987-08-28,b9f5a11b-211d-4ced-b3ba-12012c83b937,2452cf09-021b-4586-9e33-59d7d2242f31,8302-2,Body Height,180.3,cm,numeric 2002-06-27,fab43860-c3be-4808-b7b4-00423c02816b,fd113dfd-5e2c-40f2-98f3-e153665c3f53,8302-2,Body Height,165.2,cm,numeric 2009-04-07,84dd6378-2ddc-44b6-9292-2a4461bcef53,2058da3b-f7f3-4ebc-8c1e-360cd256cdcb,8302-2,Body Height,138.3,cm,numeric 2002-06-27,fab43860-c3be-4808-b7b4-00423c02816b,fd113dfd-5e2c-40f2-98f3-e153665c3f53,29463-7,Body Weight,81.8,kg,numeric 2009-04-07,84dd6378-2ddc-44b6-9292-2a4461bcef53,2058da3b-f7f3-4ebc-8c1e-360cd256cdcb,29463-7,Body Weight,24.6,kg,numeric |
and the corresponding table definition:
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
CREATE TABLE observations ( cid SERIAL PRIMARY KEY, --(*) created TIMESTAMP DEFAULT CURRENT_TIMESTAMP, --(*) date DATE NOT NULL, patient UUID REFERENCES patients, encounter UUID REFERENCES encounters, code VARCHAR(64) NOT NULL, description VARCHAR(256) NOT NULL, value VARCHAR(64) NOT NULL, units VARCHAR(64), type VARCHAR(64) NOT NULL ) ; |
Here, with --(*) have been marked additional fields with auto-generated values. These are: cid – an automatically generated primary key and created – a record creation timestamp. They will be later used by CogStack engine for data partitioning when processing the records. The patient and encouters tables have their primary keys (id field) already defined (of UUID type) and are included in the input CSV files.
Database schema – views
Next, we define a observations_view that will be used by CogStack data processing engine to ingest the records from input database:
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
CREATE VIEW observations_view AS
SELECT
p.id AS patient_id,
p.birthdate AS patient_birth_date,
p.deathdate AS patient_death_date,
p.ssn AS patient_ssn,
p.drivers AS patient_drivers,
p.passport AS patient_passport,
p.prefix AS patient_prefix,
p.first AS patient_first_name,
p.last AS patient_last_name,
p.suffix AS patient_suffix,
p.maiden AS patient_maiden,
p.marital AS patient_marital,
p.race AS patient_race,
p.ethnicity AS patient_ethnicity,
p.gender AS patient_gender,
p.birthplace AS patient_birthplace,
p.address AS patient_addr,
p.city AS patient_city,
p.state AS patient_state,
p.zip AS patient_zip,
enc.id AS encounter_id,
enc.start AS encounter_start,
enc.stop AS encounter_stop,
enc.code AS encounter_code,
enc.description AS encounter_desc,
enc.cost AS encounter_cost,
enc.reasoncode AS encounter_reason_code,
enc.reasondescription AS encounter_reason_desc,
enc.document AS encounter_document,
obs.cid AS observation_id, --(*)
obs.created AS observation_timestamp, --(*)
obs.date AS observation_date,
obs.code AS observation_code,
obs.description AS observation_desc,
obs.value AS observation_value,
obs.units AS observation_units,
obs.type AS observation_type
FROM
patients p,
encounters enc,
observations obs
WHERE
enc.patient = p.id AND
obs.patient = p.id AND
obs.encounter = enc.id
|
The goal here is to denormalize the database schema for CogStack and ElasticSearch data ingestion, as the observations table is referencing both the patient and encounters tables by their primary key. In the current implementation, CogStack pipeline engine cannot yet perform dynamic joins over the relational data from specific database tables.
Some of the crucial fields required for configuring CogStack Pipeline engine with Document data model have been marked with --(*) – these are:
observation_id– the unique identifier of the observation record (typically, the primary key),observation_timestamp– the record creation or last update time.
These fields are later used when preparing the configuration file for CogStack data processing workflow.
| Anchor | ||||
|---|---|---|---|---|
|
General information
Each CogStack data processing pipeline is configured using a number of parameters defined in the corresponding Java properties file. Moreover, multiple CogStack pipelines can be launched in parallel (see Example 3 from the Examples part), each using its own properties file with configuration. In this example we use only one pipeline with configuration specified in examples/example2/cogstack/observations.properties file.
Properties description
There are multiple configurable parameters available to tailor the CogStack data processing pipeline to the specific data processing needs and available resources. Here we will cover only the most important parameters related with configuring the input source, the output sink and data processing workflow. For a more detailed description of the available parameters, please refer to the CogStack pipelinePipeline documentation part.
Spring profiles
CogStack configuration file uses Spring profiles, which enable different components of the data processing pipeline. In our example we use:
spring.profiles.active = jdbc_in,elasticsearchRest,localPartitioning
which denotes that only such profiles will be active:
jdbc_infor JDBC input database source connector,elasticsearchRestfor using REST API for inserting documents to ElasticSearch sink,partitioningfunctionality (for data processing).
As a side note, specifying localPartitioning is optional, as, when not defined it will be used by default. We keep it here for clarity, as one of the obligatory properties to specify are the partitioner configuration.
For a more detailed description of available profiles please refer to CogStack pipelinePipeline documentation part.
Data source
The parameters for specifying the data source are defined as follows:
source.JdbcPath = jdbc:postgresql://samples-db:5432/db_samples
source.Driver = org.postgresql.Driver
source.username = test
source.password = test
In this example we are using a PostgreSQL database which driver is defined by source.Driver parameter. The PostgreSQL database service is available in the CogStack ecosystem as samples-db, has exposed port 5432 and the sample database name is db_samples – all these details need to be included in the source.JdbcPath parameter field. The information about the data source host and port directly corresponds to the samples-db microservice configuration specified in the Docker Compose files (see: examples/docker-common/docker-compose.yml and examples/example2/docker/docker-compose.override.yml) as mentioned in the Running CogStack part.
Next, we need to instruct CogStack workers how to query the records from the data source:
source.selectClause = SELECT *
source.fromClause = FROM observations_view
source.sortKey = observations_id
source.primaryKeyFieldValue = observations_id
source.timeStamp = observations_timestamp
source.dbmsToJavaSqlTimestampType = TIMESTAMP
This is where the previously defined observations_view with additional CogStack-specific fields are used (see: Advanced: preparing a DB schema for CogStack part).
Data sink
Next, we need to define the data sink – in our example, and by default, ElasticSearch is being used:
elasticsearch.cluster.host = elasticsearch-1
elasticsearch.cluster.port = 9200
Similarly, as when defining the sample database source, we need to provide the ElasticSearch host and port configuration according to the microservices definition in the corresponding Docker Compose file.
| Tip | ||
|---|---|---|
| ||
As an additional feature, security and ssl encryption can be enabled for communication with ElasticSearch. However, it uses the ElasticSearch X-Pack bundle and requires license for commercial deployments, hence it is disabled by default. |
In the next step, we specify the ElasticSearch indexing parameters:
elasticsearch.index.name = sample_observations_view
elasticsearch.excludeFromIndexing = observations_id
We specify the index name which will be used to store the documents processed by CogStack workers. Additionally, we specify which fields from the database view should be excluded from the indexing – by default, we usually exclude the binary content, the constant-value fields and the primary key from the observations_view (see: Advanced: preparing a DB schema for CogStack).
Jobs and CogStack workers configuration
CogStack pipeline engine in order to coordinate the workers needs to keep the information about the current jobs in an additional PostgreSQL database – cogstack-job-repo. Hence, similarly as when defining the source database, this database needs to specified:
jobRepository.JdbcPath = jdbc:postgresql://cogstack-job-repo:5432/cogstack
jobRepository.Driver = org.postgresql.Driver
jobRepository.username = cogstack
jobRepository.password = mysecretpassword
job.jobName = job_observations_view
The last parameter job.jobName is a default name for the jobs that will be created and is optional to specify.
Partitioner and scheduler
Another set of useful parameters are related with controlling the job execution and data partitioning:
partitioner.partitionType = PKTimeStamp
partitioner.tableToPartition = observations_view
partitioner.pkColumnName = observations_id
partitioner.timeStampColumnName = observations_timestamp
In the current implementation, CogStack pipeline engine can only partition the data using the records’ primary key (observation_id field, containing unique values) and records’ update time (observation_timestamp field) as defined in observations_view. This is specified by PKTimeStamp partitioning method types.
Apart from data partitioning, it can be useful to set up the scheduler – although it'a optional, the following line corresponds to the scheduler configuration:
scheduler.useScheduling = false
In this example we do not use scheduler, since we ingest EHRs from the data source only once. However, in case when the data is being generated in a continuous way, scheduler should be enabled to periodically run CogStack jobs to process the new EHRs. By default, the scheduler is turned off.