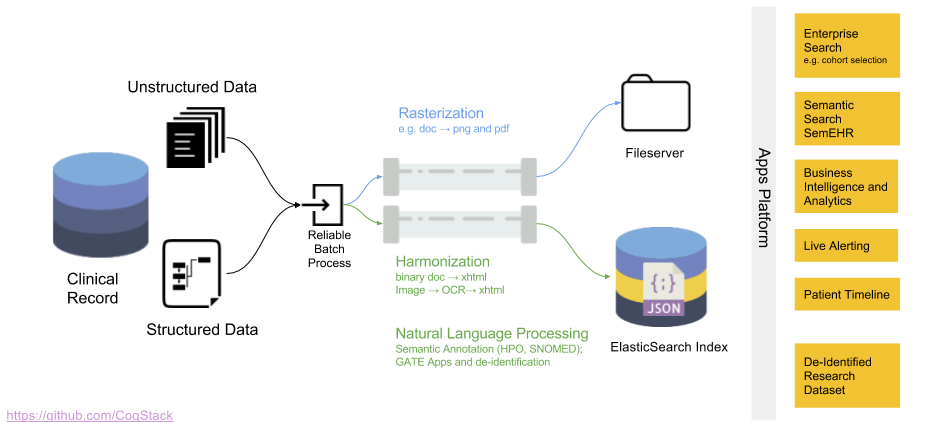
Overview
The data processing workflow of CogStack is based on Java Spring Batch framework. Not to dwell too much into technical details and just to give a general idea – the data is being read in batches from a predefined data source, later it follows a number of processing operations with the final result stored in a predefined data sink. CogStack implements variety of data processors, data readers and writers with scalability mechanisms that can be specified in CogStack job configuration.
Each CogStack data processing pipeline is configured using a number of parameters defined in the corresponding Java properties file. Moreover, multiple CogStack data processing pipelines can be launched in parallel or chained together (see Examples), each using its own properties configuration file.
| Note | ||
|---|---|---|
| ||
Please note that this documentation page is regularly updated and it corresponds to the newest version 1.3.0 of CogStack. The previous versions of CogStack and documentation can be found in the official github repository. |
| Panel | ||||
|---|---|---|---|---|
| ||||
|
Anchor engine engine
CogStack data processing engine
| engine | |
| engine |
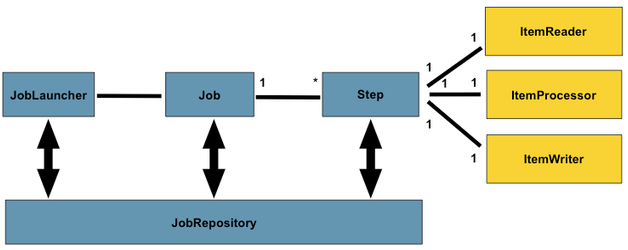
There are multiple configurable parameters available to tailor the CogStack data processing pipeline to the specific data processing needs and available resources. CogStack data processing pipeline design follows the principles behind Spring Batch. That is, there are different Jobs and Steps and custom processing components called ItemReaders , ItemWriters and ItemProcessors . A Job has one to many Step, which has exactly one ItemReader, ItemProcessor, and ItemWriter. A Job needs to be launched by JobLauncher, and meta data about the currently running process needs to be stored in JobRepository. The picture below presents a simplified version of a reference batch processing architecture.
In CogStack engine multiple data processing operations can be chained together in one ItemProcesor. All the selected data processing operations with ItemReaders and ItemWriters are later assembled in compositeSlaveStep Bean (defined in uk/ac/kcl/batch/JobConfiguration.java) according to the active Spring profiles specified in the user-defined CogStack job properties file. This allows for a significant degree of flexibility when defining data processing pipelines using CogStack and which allows for future extendability with new components.
Moreover, apart from data processing components, there are also other aspects that CogStack pipeline supports, such as data partitioning, parallel and multithreaded execution of jobs, job scheduling, etc.. All the currently implemented functionality is briefly described below in the following sections.
For more details on how does Spring Batch framework works and what functionality it offers, please refer to the official Spring Batch documentation.
Anchor document-model document-model
Document model
| document-model | |
| document-model |
CogStack data processing engine uses an internal document model to perform mapping between the input data source (supplied to item readers), item processors and output sink (supplied through item writers). The currently available document model is defined in uk/ac/kcl/model/Document.groovy file.
The current document model defines a number of available fields which are used when defining mappings in CogStack job properties files. Please refer to Quickstart tutorial to see some examples working directly with the data.
Anchor document-rec-map document-rec-map
Records data mapping
| document-rec-map | |
| document-rec-map |
The document model exposes such fields to perform the mapping from the input data source:
String srcTableNameString srcColumnFieldNameString primaryKeyFieldNameString primaryKeyFieldValueTimestamp timeStamp
These fields are used to provide direct access to the underlying record data from the source database table to the desired item processors.
In the current data model implementation, it is mandatory to provide mappings for primaryKeyFieldValue and timeStamp fields only. The remaining fields are used in docman profile.
Moreover, some database writers also rely on the document model to map the record data into output database table – please see Target SQL query part.
| Note | ||
|---|---|---|
| ||
Based on the current document model implementation CogStack data processing engine is not yet able to read records with document data represented only as files stored in the filesystem. For the moment, it hence implements a hybrid documents reader, where the documents can be stored in the filesystem with additional record meta information stored in the database (please see |
Anchor document-doc-map document-doc-map
Documents data mapping
| document-doc-map | |
| document-doc-map |
When processing documents, in addition to the standard records data mapping fields, some fields are available to perform the mapping from the input data source:
byte[] binaryContent
The binaryContent field stores the binary data of the document to be processed by selected item processor. The document can be of any of the formats that are supported by the desired item processor(s). The processed document data is later saved in associativeArray field by the active item processor (see below).
The profiles that use the functionality of these fields:
| Tip | ||
|---|---|---|
| ||
| For a better understanding on how these mappings work please refer to Quickstart tutorial or Examples part of the documentation which show the mappings working directly with the data. |
Anchor document-json document-json
Associative array for JSON mapping
| document-json | |
| document-json |
In addition to the fields which can be mapped by the user, CogStack data model defines an additional field for storing auxiliary information:
HashMap<String,Object> associativeArray
The information which cannot be handled by the standard record fields nor stored in the documents mapping fields can be represented in the associativeArray field as a key:value pair by item processors. However, some document writers, such as mapJdbcItemWriter, can directly access the elements from the associativeArray field when writing records into output database table.
Moreover, all the record fields from the specified input database table are directly mapped into this array (with key being the name of the column). Thanks to that, it is possible to generate an output JSON file (see: JSONMakerItemProcessor) which contains all the record information both originating from the input database table, containing processed document data and containing any useful auxiliary information.
In the current implementation, the data model provides such fields to store the resulting record data in JSON format:
String outputData
Such generated JSON file can be then sent directly to ElasticSearch (see: ElasticSearch sink connector).
| Tip | ||
|---|---|---|
| ||
As an example, when activating Although not available for the user for manual modifications, any resulting errors or important information generated during the text extraction will be stored in the At the end of processing, all the elements in the |
Anchor properties properties
Job properties file
| properties | |
| properties |
CogStack data processing engine is highly configurable with a large number of parameters available to tailor the data processing requirements. All the parameters are set in the Java properties file which is later parsed when launching CogStack instance. Each CogStack instance should use it's own separate properties file to avoid possible conflict with the used resources.
The properties file used by CogStack is usually divided into sections, each covering one aspect of the CogStack job or data processing pipeline. For the ease of readability, it should be organised in the following sections:
- Active profiles
- Data source with reader configuration
- Data sink with writers configuration
- Data processors with configuration(s)
- Data partitioner and data step processing configuration
- General job, execution, job repository and scheduler configuration
For an example job properties file file please refer to Quickstart or Examples part.
Anchor profiles profiles
Spring profiles
| profiles | |
| profiles |
CogStack configuration file uses Spring profiles, which enable different components of the data processing pipeline. The profiles can be divided into categories regarding the functionality they cover. They are a part of CogStack job configuration and need to be specified before launching the CogStack instance. The profiles are enabled by specifying them as a comma separated values in the property:
spring.profiles.active
The currently available profiles are listed below.
Reading the data
Anchor profile-jdbc-in profile-jdbc-in
jdbc_in
| profile-jdbc-in | |
| profile-jdbc-in |
This profile enables JDBC input database connector used for reading records from the input databases. It is one of the most commonly used profiles.
Components activated by this profile:
Anchor profile-docman profile-docman
docman
| profile-docman | |
| profile-docman |
This profile enables processing documents read as files from the filesystem while keeping their path in the database. It is used together with other profiles, as multiple components implement functionality offered by this profile.
| Note | ||
|---|---|---|
| ||
This profile is deprecated and will be redesigned. or only provided as a custom plugin. |
Processing data
Anchor profile-deid profile-deid
deid
| profile-deid | |
| profile-deid |
This profile enables de-identification process using GATE or ElasticGazetteer services.
Components activated by this profile:
Services activated by this profile:
Anchor profile-tika profile-tika
tika
| profile-tika | |
| profile-tika |
This profile enables extraction of text from documents of different formats (PDF, DOCX, ...) and from images (JPEG, PNG, ...) using Apache Tika. Please refer to Apache Tika documentation (v.1.7) for a list of supported formats.
Components activated by this profile:
| Info | ||
|---|---|---|
| ||
Apache Tika conversion tool relies on third-party software which needs to be installed on the system. These are TesseractOCR (for extracting the text from image data) and ImageMagick (for conversions between image formats). However, when running CogStack using provided docker images, these images have already the necessary applications installed. |
Anchor profile-gate profile-gate
gate
| profile-gate | |
| profile-gate |
This profile enables NLP data processing using generic applications provided in GATE NLP suite.
Components activated by this profile:
Services activated by this profile:
| Info | ||
|---|---|---|
| ||
NLP processing implemented by generic GATE application uses GateService and gateDocumentItemProcessor, which use GATE Java API. However, other NLP applications, such as Bio-LarK or Bio-Yodie, use the webservice profile for processing the data working as an external webservice application. |
Anchor profile-pdf-gen profile-pdf-gen
pdfGeneration
| profile-pdf-gen | |
| profile-pdf-gen |
This profile enables generation PDF documents from the input records.
Components activated by these profiles:
| Tip | ||
|---|---|---|
| ||
This profile is usually used together with |
Anchor profile-thumb-gen profile-thumb-gen
thumbnailGeneration
| profile-thumb-gen | |
| profile-thumb-gen |
This profile enable generation of documents thumbnails for preview.
Components activated by these profiles:
| Tip | ||
|---|---|---|
| ||
This profile is usually used together with |
Anchor profile-dbline profile-dbline
dbLineFixer
| profile-dbline | |
| profile-dbline |
This profile enables concatenation of records which are split across multiple rows in the input database.
Components activated by this profile:
| Note | ||
|---|---|---|
| ||
This profile is deprecated and will be redesigned or only provided as a custom plugin. |
Anchor profile-pdfbox profile-pdfbox
pdfbox
| profile-pdfbox | |
| profile-pdfbox |
This profile enables processing of the documents using Apache PDFBox.
Components activated by this profile:
Anchor profile-metadata profile-metadata
metadata
| profile-metadata | |
| profile-metadata |
This profile enables extraction of metadata information from the documents using ImageMagick as an external application.
Components activated by this profile:
| Info | ||
|---|---|---|
| ||
This component uses ImageMagick which needs to be present on the system. However, when running CogStack using provided docker images, these images have already all the necessary applications installed. |
Anchor profile-webservice profile-webservice
webservice
| profile-webservice | |
| profile-webservice |
This profile enables processing of the documents using an external webservice.
Components activated by this profile:
| Info | ||
|---|---|---|
| ||
NLP document processing applications Bio-LarK and Bio-Yodie are using this profile. |
Writing the data
Anchor profile-jdbc-out profile-jdbc-out
jdbc_out
| profile-jdbc-out | |
| profile-jdbc-out |
This profile enables JDBC output database connector used for writing the processed EHRs to databases to the table specified in the properties file. It uses the Document model to map directly the record data with processed fields (e.g., by Tika) from the input table directly into the output table. It uses target.Sql property directive to perform the mapping (see: Target SQL query). The record fields not covered by the provided SQL query are output as text in the JSON format as outputData field which requires manual parsing to access it.
Components activated by this profile:
Anchor profile-jdbc-out-map profile-jdbc-out-map
jdbc_out_map
| profile-jdbc-out-map | |
| profile-jdbc-out-map |
This profile enables a JDBC output database connector used for writing to databases using direct row/document mapping. Selected fields from the input table alongside the processed data are mapped to the output table according to the SQL query (as defined by target.Sql property) using the Document model. In contrast to jdbc_out , here parsing of the JSON output is not required, as only the specified fields are being mapped. Access to the other fields from the input record or access to some auxiliary fields, such as, status of Tika parsing, is therefore not available.
Components activated by this profile are:
Anchor profile-es profile-es
elasticsearch
| profile-es | |
| profile-es |
This profile is used to insert documents to ElasticSearch using the ElasticSearch Java Transport Client API.
Components activated by this profile are:
| Note | ||
|---|---|---|
| ||
This profile is deprecated. Since this profile is using ElasticSearch Java Transport Client it suffers from some minor performance issues when inserting documents in bulk. When expecting to process a large number of documents it is highly recommended to use |
Anchor profile-es-rest profile-es-rest
elasticsearchRest
| profile-es-rest | |
| profile-es-rest |
This profile is used to insert documents to ElasticSearch through exposed ElasticSearch REST endpoint using the ElasticSearch Java Low Level REST Client.
Components activated by this profile:
Services activated by this profile:
| Info | ||
|---|---|---|
| ||
This is the recommended profile to use when writing documents to ElasticSearch. |
Anchor profile-json-file profile-json-file
jsonFileItemWriter
| profile-json-file | |
| profile-json-file |
This profile enables writing documents directly to files in JSON format. It can be used in restricted scenarios when one cannot use a database as a data sink or just when one wants to operate directly on the files.
Components activated by this profile are:
Partitioning and scaling
Anchor profile-local-partitioning profile-local-partitioning
localPartitioning
| profile-local-partitioning | |
| profile-local-partitioning |
This profile enables partitioning functionality when running jobs locally on JVM. For more details please see the Data Partitioning and Running jobs sections.
Anchor profile-remote-partitioning profile-remote-partitioning
remotePartitioning
| profile-remote-partitioning | |
| profile-remote-partitioning |
This profile enables partitioning functionality when running jobs by multiple JVMs coordinated using JMS in a master-slave fashion. For more details please see the Data Partitioning and Running jobs sections.
| Note | ||
|---|---|---|
| ||
This profile is deprecated and will be redesigned. |
Anchor readers readers
Data source and item readers
| readers | |
| readers |
CogStack data processing engine can read records and documents from multiple sources. For the moment, however, only reading from databases and filesystem is supported using a generic document reader.
Anchor readers-generic readers-generic
Generic document reader
| readers-generic | |
| readers-generic |
CogStack data processing engine implements a generic document item reader documentItemReader . It is used both for reading the documents from a database table (or view) and/or filesystem. The reader extends Java Spring JdbcPagingItemReader and provides capabilities of processing documents in batches. Hence, it requires some additional configuration, such as partitioning schemes, batch size, etc., – for more information see Data partitioning.
| Info | ||
|---|---|---|
| ||
In the current implementation it is not possible to specify only the files or directories as a single data source. To read the documents directly from the filesystem their path needs to be specified within the records in the source database (one record – one document to be processed). Hence, a source database needs to be created and configured. This functionality is currently being implemented by the |
In order to read the documents from the input database, the user needs to define the SQL block that specifies the data to process. This block is composed of three parts – defined by mandatory properties:
source.selectClause– the SELECT statement clause (possibly followed by the names of the columns), e.g.:SELECT *source.fromClause– the FROM clause followed the name of the table, e.g.:FROM <in_table>,source.sortKey– the name of the column in the source database table by which the records are ordered.
The available optional properties:
- .
source.pageSize(if not specified, defaults tostep.chunkSize) – the number of rows to retrieve (per read) at a time from the input database.
| Tip | ||
|---|---|---|
| ||
As a good practice, if possible, it's advisable to set the value of |
Anchor readers-db readers-db
Database connectors
| readers-db | |
| readers-db |
CogStack supports multiple JDBC connectors as provided in Java Spring framework. The most commonly used ones here are MySQL and PostgreSQL. However, using the other ones implemented in Java Spring framework should be also possible, such as: Derby, DB2 HSQL, ORACLE, Sybase, H2 or SQLite connectors.
Spring profiles that are using source JDBC connectors:
Anchor readers-config readers-config
Connector configuration
| readers-config | |
| readers-config |
There are multiple mandatory properties which need to be provided in the job configuration to set up the source database connector handled by Hikari Connection Pool:
source.Driver– source JDBC driver class name,source.JdbcPath– JDBC path to the source database,source.username– DB user name,source.password– DB user password,source.poolSize– the size of the connection pool.
The available optional properties:
source.poolSize(default:10) – the size of the connection pool,source.idleTimeout(default:30000) – max. idle timeout value (in ms) that a client will wait for the connection,source.maxLifetime(default:60000) – max connection life time value (in ms) of a connection in the pool,source.leakDetectionThreshold(default:0) – the max. amount of time (in ms) that a connection can be out of the pool before a potential connection resource leak.
| Info | ||
|---|---|---|
| ||
The connection to used databases is made on a pooled fashion where the connection pool is handled by Hikari Connection Pool. Hence, during initialisation of CogStack a number of connections will be allocated and kept until CogStack finishes releasing the connections. The number of connections is specified by |
Anchor readers-rowmapper readers-rowmapper
Document row mapper configuration
| readers-rowmapper | |
| readers-rowmapper |
The main component in CogStack engine providing mapping between the source database, Document model and item processors is DocumentRowMapper. It uses multiple properties, configuration of which depends on the workflow, selected Spring profiles and active components.
The available mandatory properties are:
source.srcTableName– the name of the database table where the current document to be processed reside,source.srcColumnFieldName– the name of the column which stores the name or filename of the document,source.primaryKeyFieldName– the name of the column which stores the primary key for the current document to be processed (used for partitioning),source.primaryKeyFieldValue– the name of the column which stores the primary key value (used for partitioning),source.timeStamp– the name of the field which stores the timestamp value (used for partitioning).
| Info | ||
|---|---|---|
| ||
In the current implementation, due to multiple dependencies imposed by the partitioner and the deprecated |
The available optional properties (used with different item processor components) are:
elasticsearch.datePattern(default:yyyy-MM-dd'T'HH:mm:ss.SSS) – the date pattern used for compatibility when indexing documents to ElasticSearch (but it is also used by the row mapper),reindex(default:false) – used for enabling re-indexing the data (see below),reindexField(using:reindex) – the name of the field to reindex (generated from the previous step),tika.binaryContentSource(possible values:database|fileSystemWithDBPath; default:database) – specifies where the binary documents to be processed by Tika reside,tika.binaryFieldName– the name of the field where the Tika binary document output is stored,tika.binaryPathPrefix(using:fileSystemWithDBPath) – prefix of the filesystem path where the documents reside,tika.binaryFileExts(using:fileSystemWithDBPath) – possible binary file extensions to include.
| Tip |
|---|
Using the Note, included with other profiles, these will still run, but will not contribute to the final JSON, and are thus pointless. Therefore, only the 'basic' profile should be used when reindexing data. |
Anchor processors processors
Item processors and services
| processors | |
| processors |
CogStack implements a range of different data processors and services to be able to build fully customisable pipelines. Thanks to following the Spring Batch data processing patterns, it is possible to extend CogStack pipeline with custom data processors or adding additional services.
Item processors
CogStack pipeline implements compositeItemProcessor (based on Spring Batch CompositeItemProcessor) that is used to launch delegate item processors chained together. Each processor extends the functionality of the abstract class TLItemProcessor and implements the functionality of Java abstract class ItemProcessor<Document, Document>. Below are described more in details the available item processors.
CogStack engine provides the following processors:
Anchor proc-dbfixer proc-dbfixer
dBLineFixerItemProcessor
| proc-dbfixer | |
| proc-dbfixer |
Allows to merge records from a specified table in a database spanning into multiple lines (and records) into a single record.
Active in profiles:
Available mandatory properties:
lf.documentKeyName– primary key of original document,lf.lineKeyName– primary key from table with multi row documents,lf.srcTableName– source table of multi row documents,lf.lineContents– text content from table with multi row documents,lf.fieldName– output field name.
| Note | ||
|---|---|---|
| ||
This component is deprecated. and will be possibly removed in the upcoming version of CogStack Pipeline. |
Anchor proc-gate proc-gate
gateDocumentItemProcessor
| proc-gate | |
| proc-gate |
This components implements NLP data processing using generic applications from GATE suite.
Active in profiles:
Available mandatory GATE document item processor properties:
gate.gateFieldName– the name of the output JSON field into which the GATE application will output the result,gate.fieldsToGate– comma separated names of fields in SQL that will be processed by the GATE application.
Available mandatory GATE service properties:
gate.gateHome– GATE home directory for loading plugins,gate.gateApp– the target GAPP or XAPP application to be run as a GATE component of the pipeline,gate.deIdApp(with profile:deid) – the name of the GAPP or XAPP application to perform de-identification,
Available optional GATE service properties:
gate.poolSize(default:1) – number of GATE pipelines to be loaded when in multithreading mode.gate.gateAnnotationSets(when not specified – using default set for extraction) – comma separated Annotation Sets to be extracted; need to exclude to use annotations in the default set,gate.gateAnnotationTypes(when not specified – all types will be extracted) – comma separated Annotation Types to extract.
| Info | ||
|---|---|---|
| ||
This profile uses GATE suite which needs to be present on the system. However, when running CogStack using provided docker images, these images have already all the necessary applications installed. |
Anchor proc-deid proc-deid
deIdDocumentItemProcessor
| proc-deid | |
| proc-deid |
This component implements de-identification of records using GATE or custom ElasticGazetteer service.
Active in profiles:
The property deid.useGateApp controls whether to use GATE (value: true) or ElasticGazetteer (value: false) for performing de-identification.
Available mandatory properties when using GATE application:
deid.useGateApp– this needs to be set totrue,gate.deIdApp– the name of the GAPP or XAPP application to perform de-identification,deid.fieldsToDeId– comma separated list of field names to process, it maps the resulting fields to database column labels,deid.replaceFields– if value set totrue, it replaces the text strings in the fields listed bydeid.fieldsToDeIdotherwise (value:false), creates a new field called asdeidentified_<originalFieldName>.
| Info | ||
|---|---|---|
| ||
When using GATE suite to perform de-identification of the records it is also required to activate the |
| Info | ||
|---|---|---|
| ||
This profile uses GATE suite which needs to be present on the system. However, when running CogStack using provided docker images, these images have already all the necessary applications installed. |
Available mandatory properties when using ElasticGazetteer service:
deid.useGateApp– this needs to be set tofalse,deid.stringTermsSQLFront– SQL query to retrieve strings of text for masking – e.g., names, addresses, etc., ; must surround document primary key,deid.timestampTermsSQLFront– SQL query to retrieve strings of text for masking date/time values, similar as indeid.stringTermsSQLFront.
The available optional properties:
deid.levDistance(default:30) – Levenshtein distance between 1 and 100 for performing matching – the higher value the greater fuzziness,deid.minWordLength(default:3) – don't mask words shorter than this many characters,deid.stringTermsSQLBack– second part of the corresponding above Front SQL string (if required),deid.timestampTermsSQLBack– second part of the corresponding above Front SQL string (if required).
Anchor proc-json proc-json
JSONMakerItemProcessor
| proc-json | |
| proc-json |
This components is used to generate the document output in JSON format using the Document model. It is active in all profiles and used by default (to meet requirements of composite processor).
Anchor proc-meta proc-meta
MetadataItemProcessor
| proc-meta | |
| proc-meta |
This component implements extraction of document metadata, primarily the number of pages. It uses ImageMagick as an external application for this task.
Available optional properties:
metadata.eagerGetPageCount(default:false) – when set totrueinstructs to get the page count of the document.
Active in profiles:
| Info | ||
|---|---|---|
| ||
This component uses ImageMagick which needs to be present on the system. However, when running CogStack using provided docker images, these images have already all the necessary applications installed. |
Anchor proc-pdfbox proc-pdfbox
PdfBoxItemProcessor
| proc-pdfbox | |
| proc-pdfbox |
This component implements processing of documents using Apache PDFBox.
Active in profiles:
Available optional properties:
pdfbox.namespaces– namespaces to perform mapping.pdfbox.mapping– used mappings.
Anchor proc-pdf-gen proc-pdf-gen
pdfGenerationItemProcessor
| proc-pdf-gen | |
| proc-pdf-gen |
This component implements generation of documents in PDF format from the provided input. It uses LibreOffice and ImageMagick as external applications.
Active in profiles:
Available mandatory properties:
pdfGenerationItemProcessor.fileOutputDirectory– the path where the generated PDF files will be stored.
| Tip | ||
|---|---|---|
| ||
This components is usually used together with thumbnailGenerationItemProcessor using both |
| Info | ||
|---|---|---|
| ||
This component uses ImageMagick which needs to be present on the system. However, when running CogStack using provided docker images, these images have already all the necessary applications installed. |
Anchor proc-th-gen proc-th-gen
thumbnailGenerationItemProcessor
| proc-th-gen | |
| proc-th-gen |
This component implements generation of thumbnails of PDF documents for preview. It uses ImageMagick as an external applications.
Active in profiles:
Available mandatory properties:
thumbnailGenerationItemProcessor.fileOutputDirectory– the path where the generated thumbnail files will be stored.
Available optional properties:
thumbnailGenerationItemProcessor.thumbnailDensity(default:150) – the pixel density used when generated thumbnail images.
| Tip | ||
|---|---|---|
| ||
This components is usually used together with |
| Info | ||
|---|---|---|
| ||
This component uses ImageMagick which needs to be present on the system. However, when running CogStack using provided docker images, these images have already all the necessary applications installed. |
Anchor proc-tika proc-tika
tikaDocumentItemProcessor
| proc-tika | |
| proc-tika |
This component implements processing of binary documents using Apache Tika. It implements a modified Tika documents parser for processing PDF documents. It supports processing the documents either reading them directly from the specified input database table or from filesystem (see: docman profile). It uses ImageMagick (for image conversion) and TesseractOCR (for performing OCR) external applications.
Active in profiles:
Available mandatory properties:
tika.binaryFieldName– the name of the field (in the input database table) containing the document binary data,tika.binaryPathPrefix(using:fileSystemWithDBPath) – the path prefix where the document files are stored.
Available optional properties:
tika.tikaFieldName(default:outTikaField) – the name of the output field in the output database table or JSON key into which the parsed text document will be stored,tika.binaryContentSource– (values:database|fileSystemWithDBPath; default:database) – specifies where the documents to be processed are kept (setting thefileSystemWithDBPathrequires also setting thedocmanprofile),tika.keepTags(default:false) – specifies whether the document shall be parsed into XHTML (true) format or plaintext (false),tika.tesseract.timeout(default:120) – the max. timeout value (in s) when extracting the text from image documents using TesseractOCR,tika.convert.timeout(default:120) – the max. timeout value (in s) when converting the documents using ImageMagick.
| Info | ||
|---|---|---|
| ||
Apache Tika conversion tool relies on third-party software which needs to be installed on the system. These are TesseractOCR and ImageMagick. However, when running CogStack using provided docker images, these images have already the necessary applications installed. |
Anchor proc-web proc-web
webserviceDocumentItemProcessor
| proc-web | |
| proc-web |
This component implements processing of documents through an external webservice. It uses the REST API to communicate with the webservice and sends and receives the documents in JSON format.
Active in profiles:
Available mandatory properties:
webservice.endPoint– the URL for the webservice REST endpoint,webservice.fieldsToSendToWebservice– a comma seperated field names (SQL columns) to send.
| Tip | ||
|---|---|---|
| ||
NLP document processing applications Bio-LarK and Bio-Yodie are using this profile. |
Available optional properties:
webservice.name(default:defaultWSName) – the custom name of the webservice,webservice.fieldName(default:outWSField) – the name of the output field to be created,webservice.connectTimeout(default:10000) – max. timeout value (in ms) for connection to the service,webservice.readTimeout(default:60000) – max. timeout value (in ms) to receive the response from the service,webservice.retryTimeout(default:5000) – max. time value (in ms) before performing a (first) retry,webservice.retryBackoff(default:3000) – increase the last retry time using this value (in ms) before performing the next retry.
Services
Anchor service-gazetteer service-gazetteer
ElasticGazetteer
| service-gazetteer | |
| service-gazetteer |
This service implements basic de-identification functionality based on configurable Levenshtein distance between analysed fields in the records.
Active in profiles:
Used by components:
Available mandatory properties when using ElasticGazetteer:
deid.useGateApp– this needs to be set tofalse,deid.stringTermsSQLFront– SQL query to retrieve strings of text for masking – e.g., names, addresses, etc., ; must surround document primary key,deid.timestampTermsSQLFront– SQL query to retrieve strings of text for masking date/time values, similar as indeid.stringTermsSQLFront.
Available optional properties:
deid.levDistance(default:30) – Levenshtein distance between 1 and 100 for performing matching – the higher value the greater fuzziness,deid.minWordLength(default:3) – don't mask words shorter than this many characters,deid.stringTermsSQLBack– second part of the corresponding above Front SQL string (if required),deid.timestampTermsSQLBack– second part of the corresponding above Front SQL string (if required).
Anchor service-es-rest service-es-rest
EsRestService
| service-es-rest | |
| service-es-rest |
This service implements a REST client for reading and writing documents into ElasticSearch using ElasticSearch Java Low Level REST Client.
Active in profiles:
Used by components:
Available mandatory properties:
elasticsearch.cluster.host– the host name of the ElasticSearch cluster,elasticsearch.cluster.port– the port number of the cluster.
Available optional properties:
elasticsearch.index.name(default:default_index) – the name of the index in ElasticSearch under which documents are or will be stored,elasticsearch.type(default:doc)– the type of the documents (deprecated in ElasticSearch 6.0+),elasticsearch.cluster.name(default:elasticsearch) – the name of the ElasticSearch cluster,elasticsearch.cluster.slaveNodes– the list of comma-separated <host:port>values for multi-node deployments,elasticsearch.connect.timeout(default:5000) – max. time value (in ms) for connection timeout,elasticsearch.response.timeout(default:60000) – max. timeout value (in ms) when waiting for response,elasticsearch.retry.timeout(default:60000) – max. time value (in ms) before performing retry,elasticsearch.xpack.enabled(default:false) – specifies whether to enable security module in X-Pack secirity module,
| Note | ||
|---|---|---|
| ||
Please note that using ElasticSearch X-Pack security module requires obtaining a commercial license. |
Available properties when using the ElasticSearch X-Pack security module:
elasticsearch.xpack.enabled– needs to be set totrue,elasticsearch.xpack.user– the user name for logging in to the ElasticSearch cluster,elasticsearch.xpack.password– the user password,elasticsearch.xpack.security.transport.ssl.enabled(default:false) – specifies whether to use SSL encryption for communication between ElasticSearch nodes,elasticsearch.xpack.ssl.keystore.path– the path to the Java Keystore file that contains a private key and certificate,elasticsearch.xpack.ssl.keystore.password– the password to the keystore,elasticsearch.xpack.ssl.truststore.path– the path to the Java Keystore file that contains the certificates to trust,elasticsearch.xpack.ssl.truststore.password– the password to the truststore.
Anchor service-gate service-gate
GateService
| service-gate | |
| service-gate |
This service implements a GATE client for interacting with GATE NLP suite and running native XAPP and GAPP applications.
Active in profiles:
Used by components:
Available mandatory properties:
gate.gateHome– GATE home directory for loading plugins,gate.gateApp– the target GAPP or XAPP application to be run as a GATE component of the pipeline,gate.deIdApp(with profile:deid) – the name of the GAPP or XAPP application to perform de-identification.
Available optional properties:
gate.gateAnnotationSets(when not specified – using default set for extraction) – comma separated Annotation Sets to be extracted; need to exclude to use annotations in the default set,gate.gateAnnotationTypes(when not specified – all types will be extracted) – comma separated Annotation Types to extract,gate.poolSize(default:1) – number of GATE pipelines to be loaded when in multithreading mode.
| Info | ||
|---|---|---|
| ||
This component uses GATE suite which needs to be present on the system. However, when running CogStack using provided docker images, these images have already all the necessary applications installed. |
Anchor writers writers
Data sink and item writers
| writers | |
| writers |
CogStack data processing engine implements the functionality to store the processed documents both in different data sinks. This can be either databases, ElasticSearch or files. To do this. CogStack engine provides a number of item writers implementing Java abstract class ItemWriter<Document>. Depending on the job configuration, they are later chained together using Java CompositeItemWriter<> . Below are presented currently implemented database connectors with possible item writers.
Anchor writers-db writers-db
Database connectors
| writers-db | |
| writers-db |
Similarly as in case of source database connectors, CogStack supports multiple JDBC sink connectors as provided in Java Spring framework. Here also the most commonly used ones are MySQL and PostgreSQL. However, using the other ones implemented in Java Spring framework should be also possible, such as: Derby, DB2 HSQL, ORACLE, Sybase, H2 or SQLite connectors.
Spring profiles that are using sink JDBC connectors:
Anchor writers-config writers-config
Database connector configuration
| writers-config | |
| writers-config |
There are multiple mandatory properties which need to be provided in the job configuration to set up the source database connector handled by Hikari Connection Pool:
target.Driver– target JDBC driver class name,target.JdbcPathtarget.usernametarget.password
Available optional properties:
target.poolSize10) – the size of the connection pool,target.idleTimeout30000) – max. idle timeout value (in ms) that a client will wait for the connection,target.maxLifetime60000) – max connection life time value (in ms) of a connection in the pool.
| Info | ||
|---|---|---|
| ||
The connection to used databases is made on a pooled fashion where the connection pool is handled by Hikari Connection Pool. Hence, during initialisation of CogStack a number of connections will be allocated and kept until CogStack finishes releasing the connections. The number of connections is specified by |
Anchor writers-query writers-query
Target SQL query
| writers-query | |
| writers-query |
In addition to specifying the connector configuration, it is essential to also specify the target SQL query exposed by the property
target.sql
This SQL query is used to perform the mapping between the Document model and the target database table storing the processed document with selected input table fields. The query can only address the fields available in the document model and in the target database table schema.
Using the current Document model only selected fields are available to be used in the target SQL query to perform the mapping. The rest of the fields from the input table are represented as key:value in the associativeArray in the document model. Alternatively, the final JSON data can be accessed through the field outputData. Depending on the data pipeline design and requirements, the target SQL query can perform the mapping of the document data using either of the fields. Please see simpleJdbcItemWriter and mapJdbcItemWriter for more information.
Anchor writers-es-conn writers-es-conn
ElasticSearch connector
| writers-es-conn | |
| writers-es-conn |
CogStack engine also allows for writing processed directly to ElasticSearch. The documents are generated into JSON format using JSONMakerItemProcessor which allows then for easy indexing.
Spring profiles that are using ElasticSearch connectors:
| Note | ||
|---|---|---|
| ||
The ElasticSearch connector is implemented in the ElasticSearch REST service which is being used by esRestDocumentWriter (profile elasticsearchRest). The esDocumentWriter (profile elasticsearch) is deprecated. |
Item writers
CogStack implements a range of item writers to be able to build fully customisable pipelines – the currently implemented ones are listed below.
Anchor writers-jdbc-simple writers-jdbc-simple
simpleJdbcItemWriter
| writers-jdbc-simple | |
| writers-jdbc-simple |
This component implements writing of documents to the specified output database table according to the specified target SQL query. It uses Java BeanPropertyItemSqlParameterSourceProvider to perform the mapping between the direct Document model and the output table. Usually, this writer uses outputData field from the document model.
Active in profiles:
Available mandatory properties:
target.sql– SQL query to perform the mapping between the input database table, Document model and output database table
Requires also specifying the configuration properties for DB connector.
| Info | ||
|---|---|---|
| ||
When writing the generated JSON represented in |
Anchor writers-jdbc-map writers-jdbc-map
mapJdbcItemWriter
| writers-jdbc-map | |
| writers-jdbc-map |
This component implements writing of documents to the specified output database table according to the specified target SQL query. It uses a custom implementation of Java ItemSqlParameterSourceProvider<Document> to perform the mapping between the Document model and the output table. To perform the mapping, it uses available key:value in the associativeArray field from Document model.
Active in profiles:
Available mandatory properties:
target.sql– SQL query to perform the mapping between the input database table, Document model and output database table.
Requires also specifying the configuration properties for DB connector.
Anchor writers-es writers-es
esDocumentWriter
| writers-es | |
| writers-es |
This profile is used to insert documents to ElasticSearch using the native ElasticSearch Java Transport Client.
Active in profiles:
Requires also specifying the configuration properties for ElasticSearch connector (the same as for ElasticSearch REST service).
| Note | ||
|---|---|---|
| ||
| This component is deprecated. |
Anchor writers-es-rest writers-es-rest
esRestDocumentWriter
| writers-es-rest | |
| writers-es-rest |
This component is used to insert documents to ElasticSearch through exposed ElasticSearch REST endpoint using the ElasticSearch Java Low Level REST Client.
Active in profiles:
Requires also specifying the configuration properties fo ElasticSearch REST service.
Anchor writers-json writers-json
jsonFileItemWriter
| writers-json | |
| writers-json |
This component writes documents directly to files in JSON format. It can be used in restricted scenarios when one cannot use a database as a data sink or just when one wants to operate directly on the files.
Active in profiles:
Available mandatory properties:
fileOutputDirectory –the output directory where the generated JSON files will be stored
Anchor jobs jobs
Running jobs
| jobs | |
| jobs |
CogStack data processing engine offers a broad range of options to tailor the execution of the pipeline jobs according to the requirements, available resources and desired performance. All the user has to do is to set essential parameters and Spring Batch framework will take care of running the jobs, scaling their work and parallelisation. There are multiple ways to configure the running jobs where the main concepts are covered below. How to run CogStack pipeline either as as a standalone application or as a part of ecosystem is covered in Running CogStack part.
Anchor jobs-config jobs-config
General job configuration
| jobs-config | |
| jobs-config |
There are multiple parameters to configure the pipeline batch jobs execution, with the mandatory properties to set covered in the sections below.
However, there are some optional properties available:
job.jobName(default:defaultJob) – the name of the running job, useful for controlling the execution state and auditing.configuredStart.firstJobStartDate– if set, starts processing the records from the specified date,configuredStart.datePatternForSQL– the date time patter for the particular DBMS that can be cast to an appropriate timestamp variable.
Anchor jobs-execution jobs-execution
Execution modes
| jobs-execution | |
| jobs-execution |
In principle, there are two modes in which CogStack pipeline can be executed: local and master-slave mode.
| Note | ||
|---|---|---|
| ||
| The master-slave execution mode is a bit more complicated to set-up and run hence the local execution mode is the recommended one to use. |
Local mode
In this mode jobs are executed inside a single JVM instance. All the data partitioning, job execution and coordination is being handled by a single process and multiple jobs can be running in parallel or in a multithreaded mode. This is the basic mode and the recommended one to use.
This mode is activated by enabling Spring profiles:
Master-slave mode
In this mode jobs are executed in a master-slave fashion, running multiple worker JVM instances and a coordinating master JVM instance. All the step execution is being performed by the slave workers running as separate processes. Data partitioning, job controlling with workers coordination is being handled by the master JVM instance. The coordination of and communication between JVM instances uses Apache ActiveMQ messaging and integration patterns server.
This mode is activated by enabling Spring profiles:
Available mandatory properties:
jms.ip –the IP address of the Java Messaging Service (here: ApacheMQ instance),jms.username –the username to connect to the JMS,jms.password –the password to connect to the JMS,jms.requestQueueName –the name of the JMS request channel (should be unique per job),jms.replyQueueName –the name of the JMS reply channel (should be unique per job),
Available optional properties:
job.jobTimeout(default:10000000) – the max. time value (in ms) that should complete before if will be listed as failed,jms.closeTimeout(default:100000) – timeout value (in ms) before closing the connection,globalSocketTimeout– the max. time value (in ms) to specify the global socket timeout (as some JDBS drivers don't support sockets timeouts),
In addition, it requires indicating whether the running CogStack instance will be running as a master or a slave. This is being handled by configuring properties:
execution.mode(default:local) – can belocal(default) orremote(master-slave mode) and specifies the execution mode,execution.instanceType– which can bemasterorslaveand it is required when setexecution.mode=remote .
Anchor jobs-repository jobs-repository
Job repository
| jobs-repository | |
| jobs-repository |
In order to control the batch jobs execution, CogStack engine requires setting up a job repository. It stores the current and historical job execution states and allows to check and re-start the failed ones or resume jobs execution from a previously stopped state. Usually a database is used as a job repository and CogStack engine can use JDBC connectors as provided in Java Spring framework, which can be one of: PostgreSQL, MySQL, Derby, DB2 HSQL, ORACLE, Sybase, H2 or SQLite connectors. The most commonly used one however is PostgreSQL .
| Info | ||
|---|---|---|
| ||
The schema of the job repository database needs to follow the official Spring Batch Meta-Data Schema. |
Available mandatory properties:
jobRepository.DriverjobRepository.JdbcPathjobRepository.usernamejobRepository.password
Available optional properties:
jobRepository.poolSizejobRepository.idleTimeoutjobRepository.maxLifetime
| Info | ||
|---|---|---|
| ||
The connection to used databases is made on a pooled fashion where the connection pool is handled by Hikari Connection Pool. Hence, during initialisation of CogStack a number of connections will be allocated and kept until CogStack finishes releasing the connections. The number of connections is specified by |
Anchor jobs-partitioning jobs-partitioning
Data partitioning
| jobs-partitioning | |
| jobs-partitioning |
CogStack engine follows the batch processing principles as provided by Spring Batch framework. It uses data partitioning allows to split the input data into multiple smaller chunks according to the requirements and user-defined job configuration. This allows to process the data by running multiple processing jobs either as multi-threaded (local execution mode) or running in parallel as separate JVM instances (master-slave execution mode) – see Execution modes.
Available mandatory properties:
partitioner.tableToPartition– the name of the table in the input database that contains the columns used to partition the data (see:partitioner.pkColumnNameandpartitioner.timeStampColumnNamepartitioner.pkColumnName– the name of the column containing the records primary key used when partitioning the data,partitioner.timeStampColumnNameoptional) – the column name containing the records timestamp used when partitioning the data,source.dbmsToJavaSqlTimestampType– since different DBMS interpret the SQL standard for time differently, is is necessary to explicitly specify, the date type that the database is using. E.g.: PostgreSQL:TIMESTAMP, SQL Server:DATETIME.
| Note | ||
|---|---|---|
| ||
For the moment, partitioning the data using only primary key does not work properly, hence partitioning using both timestamp and primary key ( partitioner.partitionType = PKTimeStamp ) is the recommended option. |
Available optional properties:
partitioner.gridSize(default:1) – specifies the number of data blocks to create to be processed by (usually) the same number of workers – e.g., for 10 rows to be processed, settinggridSizeto 5 will give 10 / 5 = 2 rows per thread,partitioner.partitionType(values:PKPKTimeStamp; default:PKTimeStamp) – the type of partitioning method ; for the momentPKTimeStamponly is fully supported.partitioner.preFieldsSQL– required prefix on some types of used databases (e.g., SQL Server:TOP 100 PERCENT),partitioner.maxPartitionSize– if set, overrides the grid size and sets the max number of rows per partition (warning: if used, can result in generating large numbers of partitions per job).
Moreover, there are available some optional parameters, but used when performing remote partitioning in master-slave execution mode:
partitioner.partitionHandlerTimeout(default:0) – the timeout value (in ms) to receive messages from the server.
Anchor jobs-step jobs-step
Data processing step control
| jobs-step | |
| jobs-step |
CogStack engine also exposes parameters to tailor the step execution for when configuring pipeline jobs.
Available optional properties:
step.chunkSize(default:50) – defines commit interval in step, i.e., to process this many rows before writing results to the output sink and updating the jobs repository,step.skipLimit(default:5) – the total number of exceptions that can be thrown by a job before it fails,step.concurrencyLimit(default:2) – the max. size of the thread pool for running multithreading partitions.
Anchor jobs-scheduling jobs-scheduling
Scheduling
| jobs-scheduling | |
| jobs-scheduling |
Another useful feature that CogStack implements is running jobs in a scheduled fashion according to the user configuration. By default, scheduler is off and CogStack Pipeline is run in a local execution mode.
Available optional parameters:
scheduler.useScheduling(default:false) – specifies whether run CogStack with or without job scheduling,scheduler.rate(when:scheduler.useScheduling = true) – the cron scheduling rate pattern, a list of six single space-separated fields representing second, minute, hour, day, month, weekday; E.g., "0 0/30 8-10 * * *" – 8:00, 8:30, 9:00, 9:30 and 10 o'clock every day,scheduler.processingPeriod(default:777600000000ms (9000 days)) – if set, process records in the time frame of the provided number of milliseconds from last successful job/first timestamp/start date.
| Note | ||
|---|---|---|
| ||
When running CogStack with scheduler enabled the application needs to be stopped manually to finish. Please note, that when killing the CogStack process, all the information about the current job execution will not be persisted in the job database. |
| Tip | ||
|---|---|---|
| ||
As an alternative to running CogStack with the internal scheduler enabled, one can also run CogStack without it, but configuring a |
Anchor issues issues
Known issues
| issues | |
| issues |
Anchor issue-timezone issue-timezone
Incorrect document timestamp in ElasticSearch
| issue-timezone | |
| issue-timezone |
CogStack Pipeline is preferably being run inside a container. The docker containers are by default using UTC time. Hence CogStack jobs in Docker containers are running in UTC, and when the documents are ingested into the Elastic index, they’re ending up with the date fields being one hour ahead of expected. Eg. the document added field would be actually 1 hour in the future compared to BST.
The solution here would be to run the CogStack Pipeline container with setting explicitly the time zone, e.g. in the appropriate docker-compose file (thanks Phil Davidson (Unlicensed)). More information can be found on ServerFault discussion .